


Google [GOOG] has become a full stack AI company. It uses its own data to train its own algorithms running on its own chips deployed on its own cloud. The result is that Google is able to innovate very quickly in AI and deploy it ahead of its peers—just like Apple [AAPL] took full control of OS and chip development for the iPhone. By becoming world-class at four layers of the tech stack, Google’s AI is now harder to catch than ever.
Data
Data is the fuel for AI, and Google owns some of the largest data sets in the world. The company operates seven services with over a billion monthly active users: Android, Chrome, YouTube, Gmail, Google Maps, Google Search, and Google Play. In addition, Google Translate and Google Photos are used by over 500 million people each. By operating such a diverse range of services, Google collects data of various types: text, images, video, maps, and webpages—helping the company master not just one kind of AI, but AI across various use cases.
Just as important as the data are the apps, which Google also owns. The apps are the front end to algorithms, giving Google’s AI efforts a tremendous distribution advantage. A startup might achieve a breakthrough in an AI vertical, but reaching hundreds of millions of users could take years. The same breakthrough in Google’s hands could be “turned on” for a billion users overnight. Users benefit immediately, while Google’s products become sticker and more valuable.
Algorithms
At its core, Google is an algorithms company—it invented Page Rank, the algorithm behind Google Search. Not surprising, Google was one of the first companies to adopt deep learning and arguably is the industry leader when it comes to deep learning research. Google, along with its UK subsidiary, DeepMind, has created novel deep learning architectures that address a wide range of problems, notably:
- Inception — a convolutional neural network that is more than twice as accurate as and 12 times simpler than prior models;[1]
- Neural Machine Translation – a deep learning based translation system that is 60% more accurate than prior approaches;
- WaveNet – a deep learning voice engine that generates spoken audio approaching human level realism;
- RankBrain – a method to rank web pages using deep learning that is now the third most important ranking factor for Google Search; and
- Federated learning – a distributed deep learning architecture that performs AI training on smartphones instead of relying exclusively on the cloud.
While other companies like Facebook [FB] and Microsoft [MSFT] also have created novel deep learning algorithms, Google’s research breadth and user scale are unmatched in the industry. By publishing the results, Google further cements its reputation as the leader in AI, attracting the next wave of talent and thus creating a fly-wheel effect in algorithm development.
Hardware
In 2016, Google announced that it had built a dedicated processor for deep learning inference called the Tensor Processing Unit (TPU). The TPU provides high performance in deep learning inference while consuming only a fraction the power of other processors.
Google’s first generation TPU can perform 92 trillion operations per second and consumes 75 watts of power: its per watt performance equates to 1.2 trillion operations per second. In comparison, NVIDIA’s [NVDA] latest Volta GPU performs 120 trillion operations per second but uses 300 watts of power: its per watt performance is only 0.4 trillion operations per second. In other words, Google’s TPU is 200% more power efficient than NVIDIA’s GPU for the same performance, as shown below.
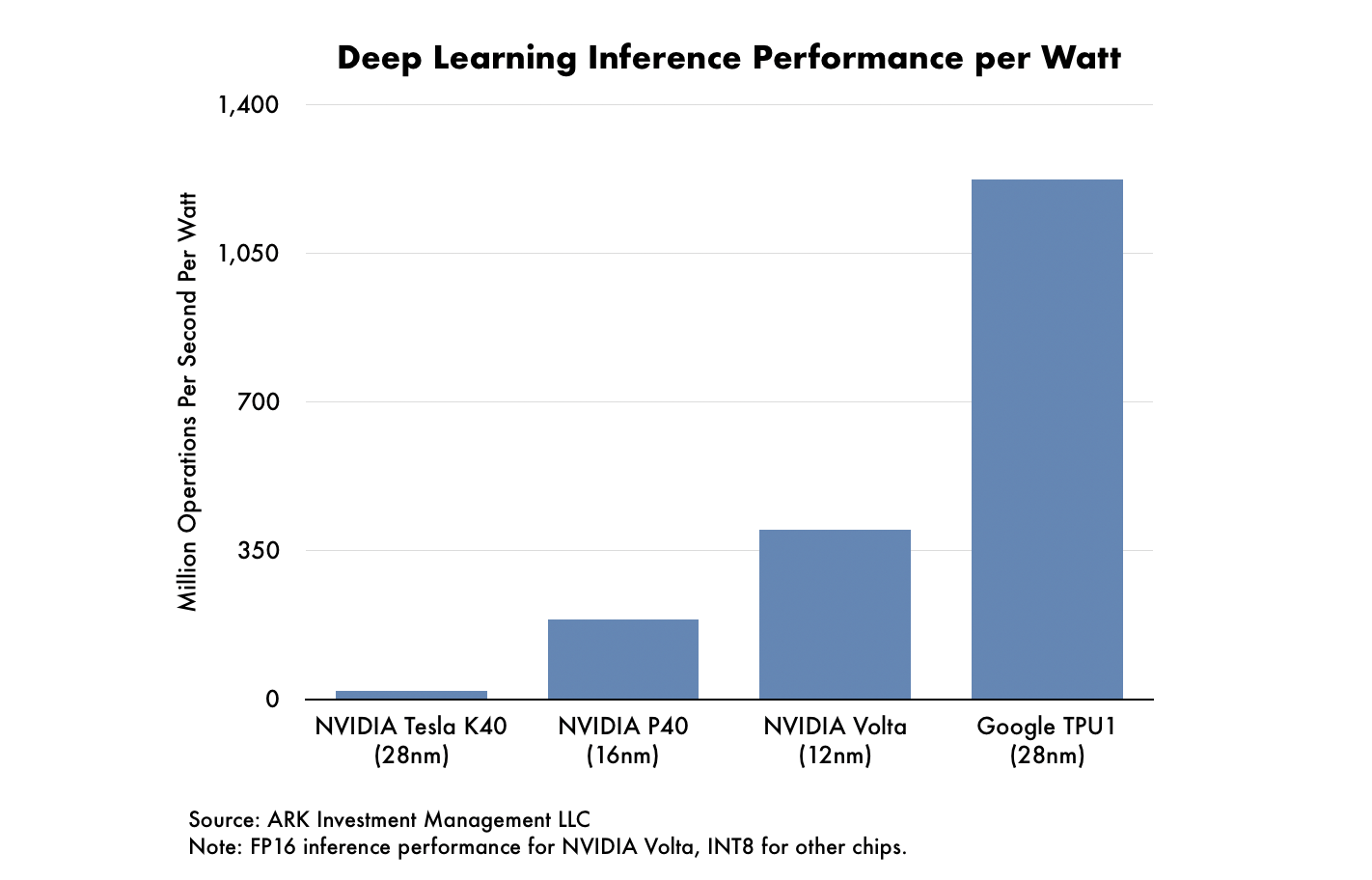
In May, Google announced its second generation TPU with the higher precision floating point number format, allowing it to perform deep learning training as well as inference. Developers can use it both to develop algorithms and to execute them, in theory eliminating any need for GPUs.
Google’s decision to bring chip design in-house has a direct parallel in the smartphone market. In 2010, Apple switched from third-party to Apple-designed System on Chips (SoCs) for its iPhone and iPad products, giving it a significant performance and go-to-market advantage over competitors. For example, in 2013 Apple designed and shipped a 64-bit ARM SoC a full generation ahead of competitors, nearly doubling the iPhone 5S’s performance relative to other smartphones while enabling new security features like Touch ID.
Google is already seeing a similar benefit. While competitors are using off the shelf processors for deep learning, Google’s TPU provides higher throughout, reduced latency and, perhaps most importantly, reduced power consumption. Because data center construction is Google’s largest capital spending line item and power its highest operating cost, the TPU meaningfully reduces both Google’s capex and opex.
Cloud
In the cloud computing business, specifically Infrastructure-as-a-Service (IaaS), Google currently is in third place, behind Amazon [AMZN] and Microsoft. One space in which Google leads, however, is cognitive application programming interfaces, or APIs.
Cognitive APIs leverage the power of the cloud to perform narrow AI tasks such as image recognition, text transcription, and translation. Unlike IaaS, which serves up commodity hardware in the most cost effective manner, the performance of cognitive API varies significantly from one vendor to another, a function of the algorithms, training data, and underlying hardware. Based on ARK’s research, these three factors favor Google: it has the most advanced algorithms, the largest dataset thanks to multiple billion-plus user platforms, and the most powerful and efficient hardware thanks to its TPU.
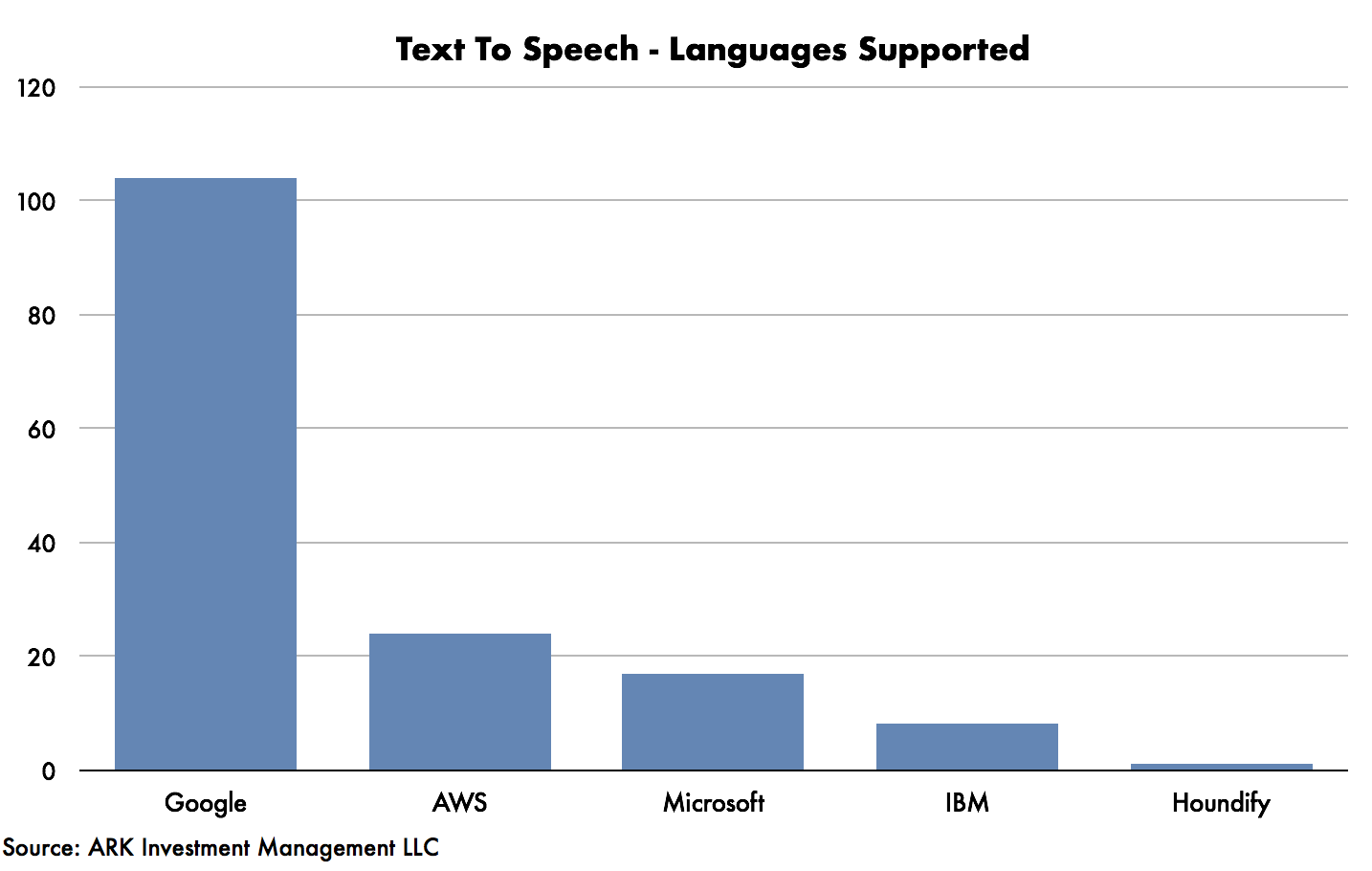
For example, Google’s translation API supports more than 100 languages in text-to-speech translation, more than four times those of AWS, its nearest competitor. In September 2016, Google added support for neural machine translation, the most accurate, deep-learning-based service, for popular languages. According to Google, the TPU was critical to enabling the new system by providing high performance, lost cost, and low latency. Its “full stack” – algorithms, data, hardware, and cloud – was critical to giving it the competitive advantage in this high performance, web-scale service.
Google’s primary weakness today is in client devices. Because Google provides the software and services but must work with hardware vendors, some of them hostile, to reach customers. When Apple dropped Google Maps as the default maps app on the iPhone, for example, Google lost a significant number of valuable customers. It is addressing this weakness by investing aggressively in its own hardware products, such as the Google Home smart speaker, the Pixel smartphone, and Nest connected devices. This strategy will take time to reach a meaningful level of penetration.
Google’s AI efforts have built a fully integrated company that spans algorithms, data, hardware, and cloud services. This approach helps funnel the world-class AI of Google’s consumer products to its enterprise offerings, providing Google Cloud with a competitive edge. Bringing chip design in-house increases Google’s AI moat by improving performance, lowering latency, and reducing cost. Perhaps most critically, vertical integration enhances its organizational agility: Google can steer all parts of its organization to bring a new product or service to market. Consequently, Google’s AI will be at the forefront of the innovation for years to come.
Related Research


Google's Driverless Car: A Massive Data Request
